

Neurys AI Solves Problems ChatGPT and Claude Can't (Plus: Epic Tower of Hanoi Solution)
See our modular AI system outperform GPT-4o and Claude 3.7: nails tricky letter counts, spawns new experts on demand, and solves a 20-disc Tower of Hanoi, all in one take, all locally on a Mac mini.
This summer marks a bright milestone for the Neurys AI team: we’re showcasing the first public demos of our self-evolving, modular architecture in action.
We’ve listened to the debate ignited by Apple’s “Illusion of Thinking” paper and Gary Marcus’ critique that today’s LLMs parrot at scale. We agree. Raw token prediction alone can’t deliver the kind of crisp, verifiable reasoning real-world systems demand. So we're building something different.
Our opportunity: modular, self-evolving AI
Instead of a single giant model, the Neurys AI system uses a conductor LLM that dynamically spins up small specialist experts (rule-based, generative, or ML) exactly when they’re needed. And if a new expert is needed, the system's Architect adds one. Each expert is auditable and small enough to train or swap on-device. The result is a system that thinks like a team, not a black box.
The challenge we’re tackling
In this demo, we show how traditional, monolithic LLMs can still stumble on grade-school puzzles; for example, ChatGPT-4o miscounts the 'l's in “Lilly’s little lullaby."
Then we show how our system, a self-evolving modular AI, has no problem tackling the task—it gets it right on the first try.
But that's just the beginning. We then show, in the same session, how the system can evolve by creating and adding new experts to solve new unique problems; in this case, the Tower of Hanoi.
For reference, most AI systems break down on longer, complex tasks. Here's how Claude does on the Tower of Hanoi challenge as the number of rings increases.
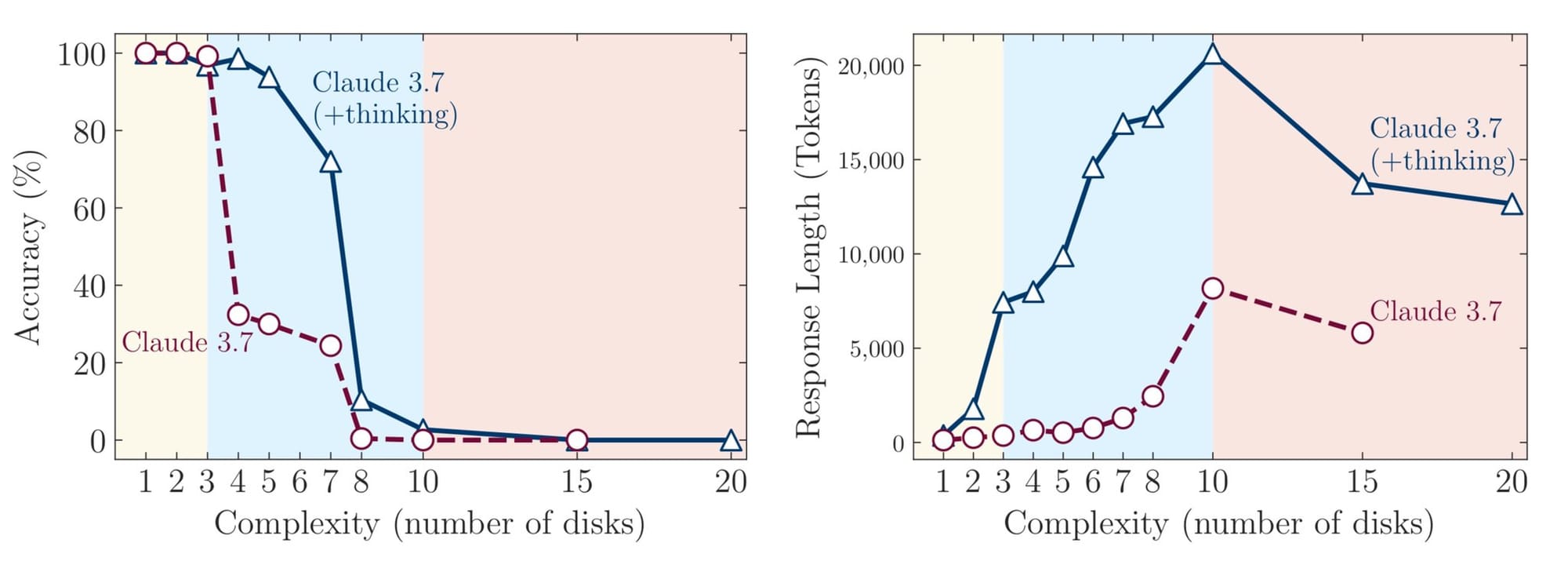
In our demo below (at 2:41), you'll see our system self-evolve to create its own niche expert, dedicated to being really good at Tower of Hanoi, and solve for TWENTY discs. All running locally on a Mac mini. We would insert a mic drop emoji here, but that wouldn't be professional.
Demo highlights
- Letter-count mastery: Our system nails the “Lilly’s little lullaby” exercise on the first try while GPT-4o needs three attempts.
- Math on demand: Existing arithmetic experts handle fresh equations without extra prompting.
- On-the-fly skill creation: When asked to solve Tower of Hanoi with two discs, the conductor notices the gap, autogenerates a brand-new expert, and verifies it live.
- Scaling to 20 discs: That newborn expert then tackles a 20-disc version—an exponential jump—without breaking a sweat.
- Single session, zero edits: Every step unfolds in one recording, underscoring our verification loop and transparent reasoning.
Why this matters
- Accuracy first: Narrow experts + iterative verification crush easy-to-miss errors. Miscounting the number of letters in a phrase may not seem like a big deal. But if your AI can't get that right, what else is it getting wrong?
- Resource-friendly: Only the relevant micro-models load into memory—ideal for edge devices.
- Continual learning: The system promotes or retires experts just like a healthy team evolves.
- Increased Interpretability: Every move is logged and auditable.
What’s next
We're actively seeking AI researchers to contribute to our work via our PhD fellowship or internship programs.
Neurys AI Newsletter
Join the newsletter to receive the latest updates in your inbox.

){kind=link}