
Our Technology
Neurys AI’s novel architecture powers self-evolving, modular AI systems. With orchestration, verification, and hardware-agnostic execution, it continually learns, adapts, and expands expertise in real time for unmatched accuracy and personalization.
How does Neurys AI work?
Neurys AI uses a proprietary modular AI system that enables advanced reasoning, continual learning, skill expansion and refinement, and output verification. Leveraging open source models and user-assisted RL training, Neurys AI adapts and improves in real-time, unlocking unprecedented personalization, accuracy, and expertise.
We’re not training new models—we’re creating a dynamic system that draws enhanced AI performance & behavior out of the current state-of-the-art. As frontier models continue to improve, so will the capabilities of Neurys AI.
Our novel architecture
At the core of what makes Neurys AI so powerful is its iCon architecture (based on a proprietary* framework), which allows for the design of AI-orchestrated systems composed of interoperable expert modules of any software type and modality (e.g., generative AI, ML, rule-based algos).
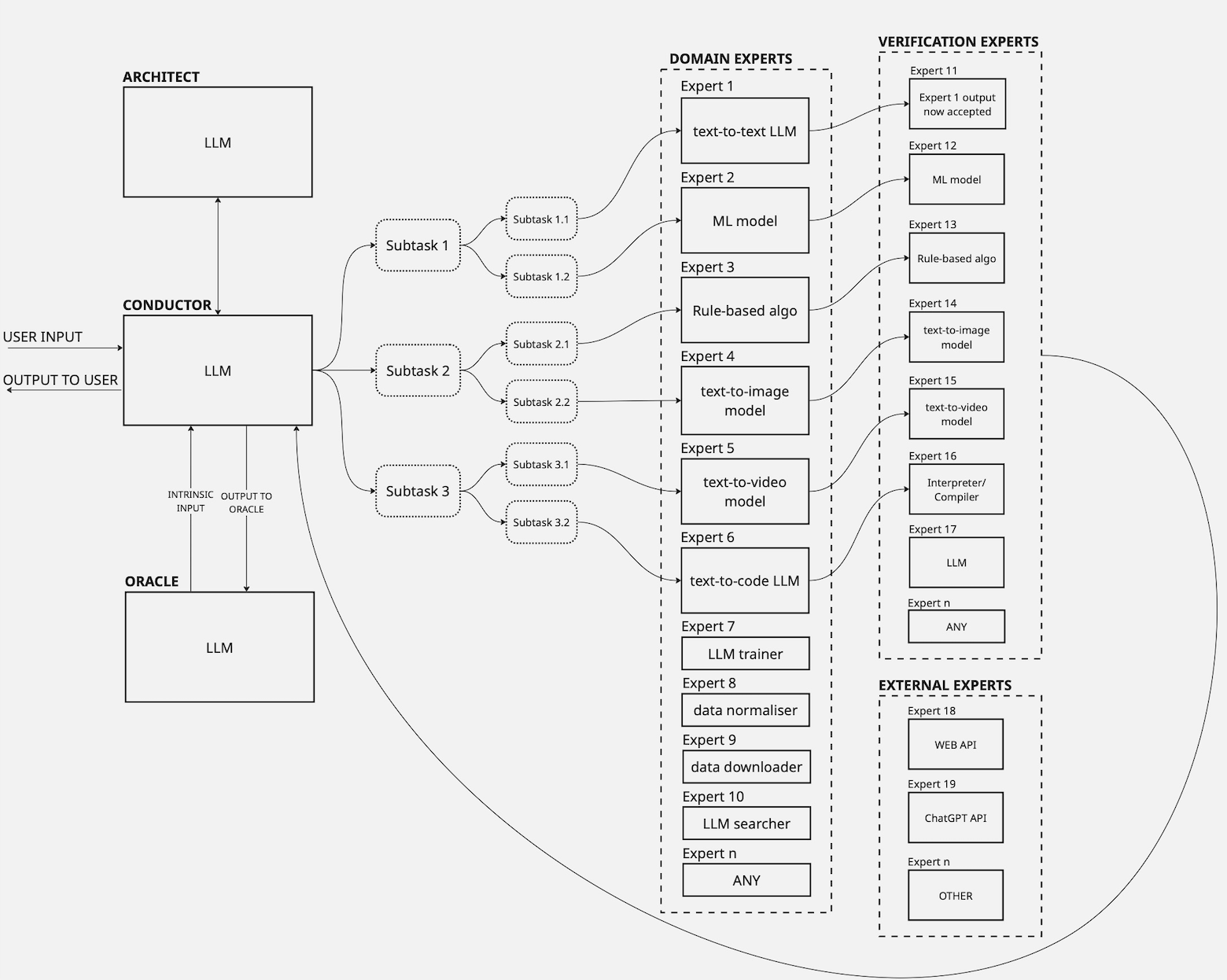
Neurys AI's iCon architecture in detail
- Orchestration A Conductor LLM decomposes tasks and routes subtasks to niche Domain Experts, leveraging best in open-source models
- Verification Every expert is paired with a verification module to mitigate hallucinations and ensure accuracy
- Knowledge gap identification System self-recognizes knowledge gaps (extrinsic via user input or intrinsic via internal Oracle)
- Self-evolution Architect directs addition of new skills/tools and/or improved capability with existing skills/tools to address knowledge gap (e.g., it can find a dataset online and train a new expert on that, or it can download an existing niche expert)
- Deterministic outputs Neurys AI's use of branchless, batch-invariant integer arithmetic overcomes the challenges associated with nondeterminism in LLM inferencem, via our patented* FIONa boolean-to-math conversion (US11029920B1).
- Hardware-agnostic execution Powered by patented* tech for increased speed and parallelizable execution on any hardware.
- Global Context Sharing Our DisNet server system enables multi-device orchestration and global context sharing across the modular system, so all the modules have access to the same info